


Choose a template. Pick some scene designs. Add some media footage. Select a music track. And ta-da! – you’ve created a video using Lumen5. But there’s more than meets the eye. The Luminary team does all the heavy lifting so you can enjoy the magical process of video creation. Recently, one of our Software Developers, Antoine, created a piece of software to change and improve how Lumen5 renders video—and made it open source to give back and make it accessible to the greater software community.
From the perspective and lens of Antoine, our Software Developer:

Want to learn more about Antoine?
We did a little Lumen5 spotlight on him!
When you are ready to publish a Lumen5 video, our rendering process begins, creating a high-quality MP4 file that’s ready to be shared. In the last couple of weeks, me and my colleagues in the Luminary team at Lumen5 have been working on an initiative to improve the speed at which we deliver video renders and reduce the amount of rendering errors that users experience.
As part of this, we are releasing a new core part of our rendering system as an open source library: Framefusion. Framefusion is built to efficiently extract frames from videos in our typescript + node backend. Read on to learn about the technical challenges behind video creation at Lumen5.
Rendering Videos at Lumen5
After a user is done creating their video in Lumen5 the rendering step begins. Frame by frame, we extract images from input video and render all necessary text and graphics. It’s crucial that we are able to extract frames from input video, which can be stock media or user uploaded footage.
2021: From Chrome to Node rendering
Circa 2021, our system used headless Chrome to render videos, but we migrated to a new node-based system to have more control and performance. Since our system is heavily based on the DOM, we polyfilled browser APIs such as <canvas/> and <video/> in the node environment. Ever since we used the node version, we relied on FFmpeg to extract all the frames we required in a video. This approach turned out to be simple at first, but we soon ran into bugs, edge cases, unexpected durations and frame rates.
2023: Moving from FFmpeg to Framefusion
To simplify the creation of a new <video/> element in node, we really wanted a library that could give us a frame at a specific time in a video with a low performance cost. My colleague Stepan found Beamcoder , which provides node bindings for ffmpeg’s native libraries (libav*). We saw this as a new way we could read videos.
As a first step, I built a prototype version of the library to validate that Beamcoder is working at all. Once it started working, we have put more effort into the project to make it production-ready, also bringing in Manu, a very skilled developer and the original writer of our <video/> element polyfill on the project. We set up CI through github actions to make sure we don’t re-introduce bugs all the time.
Anatomy of a MP4
For our team, moving from the FFmpeg API to Beamcoder’s API meant that the team had to learn about the inner workings of mp4 files. FFmpeg had the advantage of hiding this complexity, but we could not further ignore it, since we had too many issues related to frame timing.
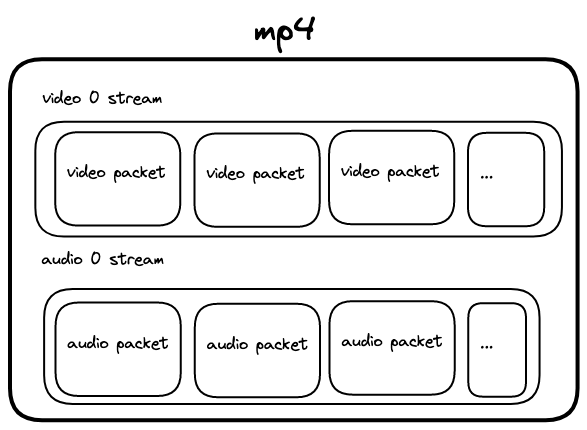
Streams
MP4 files are basically a container that can contain multiple streams of different type. These can be video, audio, text and more. In Framefusion, we find the first video stream and use it as our output. Generally, this is stream 0, but we have been surprised in production with cases where it’s 1.
Packets
Streams themselves contain packets, which contain the actual frame, audio or text data. For frames, each packet has a PTS – Presentation Time Stamp, which is the exact time at which the frame should start being displayed. One of the drawbacks of our previous FFmpeg approach is that unless filtering for a constant frame rate, we were not able to get the PTS and thus it was difficult to validate that FFmpeg was providing the right frames.
I-frames, P-frames, B-frames
MP4 typically contain a few I-frames, which contain a full image. To save space, other frames are either compressed using data from the previous frames (P-Frames) or from both previous and future frames (B-frames.). MP4s uses all sorts of techniques to compress video, which you can learn about here. A decoder is necessary to decompress and turn this data into actual pixels.
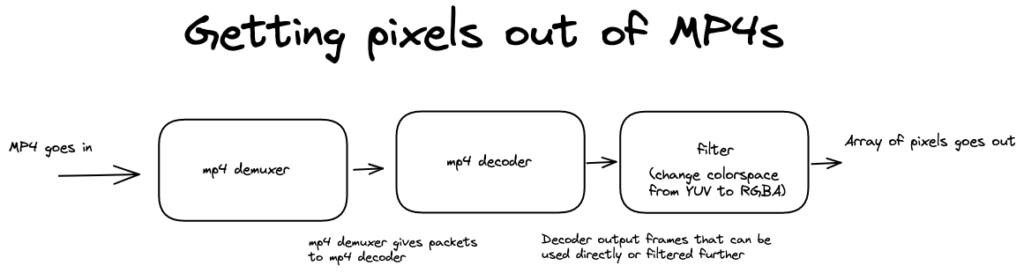
Demuxing, decoding and filtering
To read video files, the first step is to open a file using a demuxer. The demuxer reads the file and can provide us with metadata (duration, number of streams, width, height, etc.). It also allows us to read packets, which can be sent to a decoder. At the output of the decoder, we add a filter to convert from the YUV colorspace to RGBA colorspace. This RGBA data can readily be used to create image data to use in an HTML <canvas/>.
Using Framefusion
To use Framefusion, install it in your JS/TS project:
yarn install '@lumen5/framefusion'Here is how it should look like to import and use Framefusion:
import { BeamcoderExtractor } from '@lumen5/framefusion';
async function run() {
const extractor = await BeamcoderExtractor.create({
inputFile: './video.mp4'
});
// Get frame at a specific time (in seconds)
const imageData = await extractor.getImageDataAtTime(2.0);
// Now you can use image data!
}
run();Our API is intentionally simple and minimal, so we can potentially support different backends at some point and keep the same functionality.
Roll out process
We gradually introduced Framefusion for our production renders. As I’m writing this, 100% of our videos first try to render with Framefusion and fallback to our previous system in case of errors.
We reached a few interesting edge cases as we rolled out:
- We were expecting all videos in our system to be at stream 0, but some files actually had audio instead of video in stream 0, so we had to adapt Framefusion to be able to read from other streams (1,2,3, etc.).
- We encountered some performance issues with excessive seeking due to bugs in our packet reading algorithm. We then fixed Framefusion to seek only when required.
- Beamcoder’s decoder does not support feeding frames in decreasing PTS order, so we had to instantiate a new decoder when jumping back to the beginning for our looping videos.
After solving these bugs, Framefusion’s performance is similar to our previous FFmpeg approach, but we got rid of our timing issues and we dramatically simplified our <video/> implementation. As time progress, we’ll be fixing bugs that come up. We will use it both to render videos and generate previews for videos.
Conclusion
Developing Framefusion was really fun, especially learning everything that’s required to read video files. Since our team is always looking to contribute to our open source, we are releasing Framefusion on github. We hope you find this library useful for whatever use case you have. If you do start using Framefusion, don’t hesitate to reach out in github issues.
Check out our full repo at: https://github.com/Lumen5/framefusion
If you are interested in Beamcoder, visit: https://github.com/Streampunk/beamcoder




